Visual studio code, pipenv를 활용한 강화학습 개발 환경 꾸리기(5)
CartPole
이전까지 우리는 여러 패키지 설치와 VS code 세팅을 진행하였습니다. 거의 다 왔습니다. 드디어 강화학습 예제를 돌려볼 대부분의 준비가 완료되었습니다.
이번 포스트에서 따라해볼 예제는 CartPole입니다. 튜토리얼 사이트를 들어가 보면 애니메이션이 나옵니다. 이 애니메이션에서는 카트가 열심히 막대기를 세우고 있네요. 그럼 우리는 이 막대기를 세우는 게임을 신경망에 학습시켜 보겠습니다.
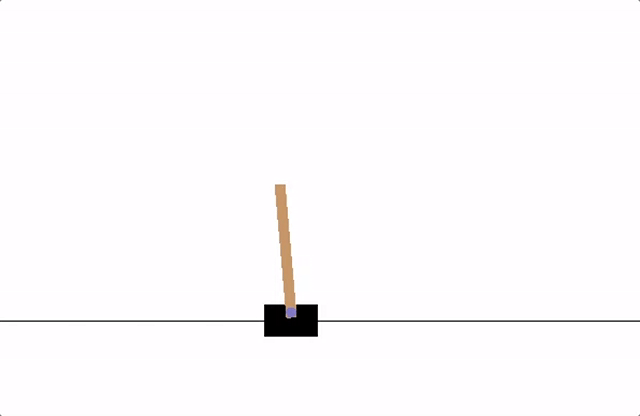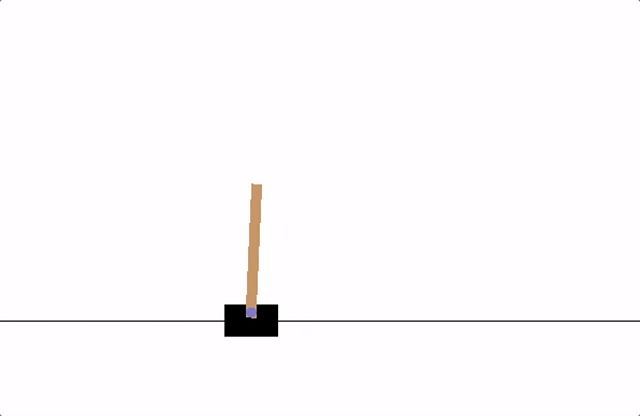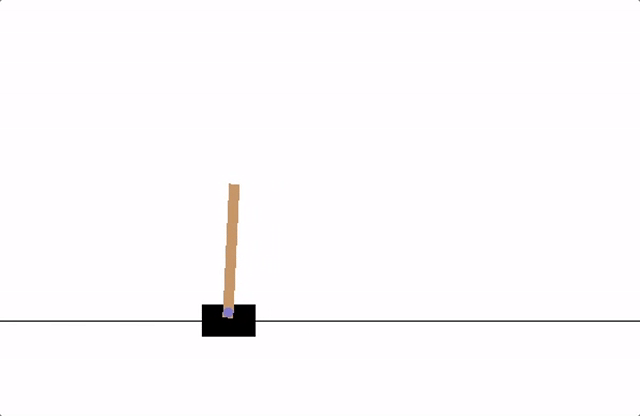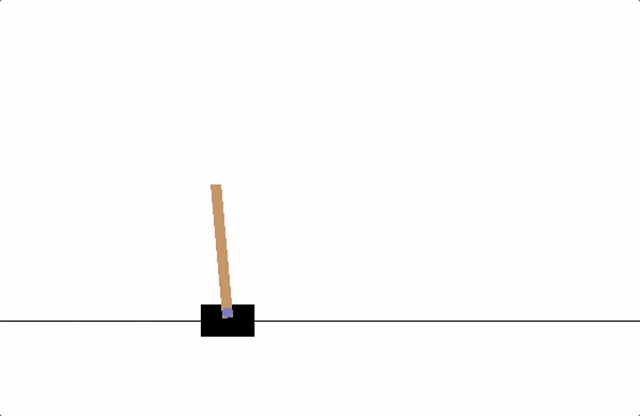
이 CartPole 예제를 돌리기위해서 필요한 패키지가 있습니다. gymnasium 입니다.
gymnasium
gymnasium은 강화학습 연구개발을 위한 패키지로 여러 강화학습 환경을 제공해줍니다. CartPole 역시 이 패키지 안에있는 하나의 환경입니다. gymnasium을 사용하기 마찬가지로 pipenv를 이용하여 설치해 봅시다.
pipenv install gymnasium[classic_control]
gymnasium의 예전 이름은 OpenAI Gym입니다. 예전 버전에서 대규모 업데이트를 진행하였고 OpenAI Gym은 더 이상 유지보수가 이루어지지 않는다고 합니다.
카트가 이리 저리 움직이는 모습이 마치 게임을 플레이 하는 것 같군요. gymnasium에는 수많은 게임 혹은 환경들이 구현되어있고 classic_control에는 5종류의 환경이 구현되어있습니다.
classic control 환경까지 설치가 되었으니 이제 Pytorch의 CartPole 예제의 코드를 복사해오겠습니다.
마찬가지로 코드 블록을 하나씩 Jupyter Notebook에 복사해 주세요. 그리고 Run All을 누르면 매번 에피소드마다 얻은 점수를 기록하는 그래프가 그려지는 것을 실시간으로 보실 수 있습니다.
드디어 우리는 처음으로 인공 신경망에게 강화학습을 시켜봤습니다!
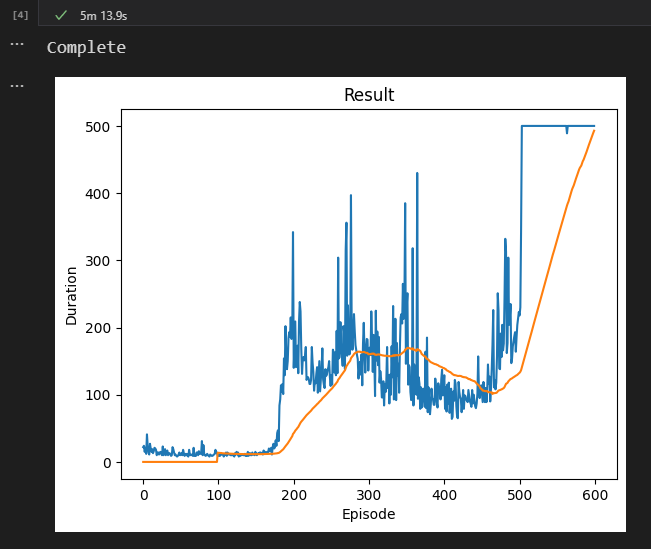
그래프에 대해 간단히 살펴볼까요? 파란색 그래프는 막대기가 서있던 총 시간 [Duration]을 의미합니다. 주황색 그래프는 파란색 그래프의 100번 Episode의 평균을 의미합니다.
CUDA를 사용했을 때 기본 에피소드 횟수는 600번입니다. 혹시 자신의 컴퓨터 GPU가 CUDA를 지원하지 않으면 50번의 에피소드만 학습합니다.
처음에는 막대기를 잘 세우지 못하다가 약 190번 에피소드 쯤에 성능이 좋아지고 500번째 에피소드 이후부터는 에피소드 강제 종료 점수인 500 duration 동안 잘 서있는 것을 볼 수 있군요.
렌더링을 해보겠습니다. 렌더링은 모니터에 게임 등의 화면을 출력하는 것을 의미합니다. 즉 막대기를 세우는 위 애니메이션을 모니터에 직접 띄워보겠다는 것이겠죠.
gymnasium에서는 단순히 환경을 만들 때 render_mode를 human으로 설정하는 것으로 렌더링이 가능합니다. 좀 더 자세히 말씀드리면 render_mode가 human일 때 env.step() 함수가 내부에서 env.render() 함수를 자동으로 호출합니다.
아마 OpenAI Gym 시절에는 자동으로 render 함수를 부르지 않았던 것으로 추측됩니다. gymnasium에 대한 더 자세한 내용은 다음 포스트 시리즈에서 다뤄볼 예정입니다.
#env = gym.make("CartPole-v1")
env = gym.make("CartPole-v1", render_mode="human")
# set up matplotlib
is_ipython = 'inline' in matplotlib.get_backend()
if is_ipython:
from IPython import display
plt.ion()
pygame window라는 새로운 창이 열리고 카트가 열심히 움직이는 모습이 보이시나요? 그렇다면 성공입니다!