gymnasium 패키지로부터 독립하기(1)
Import
이번 포스트부터 gymnasium 패키지에 대해서 알아볼 예정입니다. 아이러니하지만 더 잘 알아보기 위해 예제 코드에서 gymnasium 패키지를 걷어내보는 것도 좋은 공부가 될 것 같습니다.
예제 코드의 가장 첫줄 gymnasium 패키지를 import하는 부분을 주석처리하고 F5를 눌러서 실행해 보면
당연히 gym 패키지도, make() 함수도 찾을 수 없습니다. make() 함수로 부터 반환되는 클래스도 없어 env 변수에 아무것도 담을 수가 없습니다.
CTRL+F 키를 이용하여 env 변수를 찾아볼까요?
코드에 총 7 군데 사용되었습니다.
몇개 되지 않습니다.
지금부터 이 7개의 env 변수를 하나씩 삭제해보겠습니다.
Make
env = gym.make("CartPole-v1")
14 라인에서는 env 변수에 CartPole이라는 환경을 담는 동작을 수행합니다.
gymnasium에서 제공하는 환경은 사용하지 않을 예정이므로 이 라인도 주석처리하겠습니다.
make() 함수에 대한 자세한 설명은 링크를 통해 알 수 있습니다.
Action space
# Get number of actions from gym action space
n_actions = env.action_space.n
다음 76 라인은 친절하게 주석이 달려있습니다. 환경안에서 강화학습 주체가 취할 수 있는 action의 수를 의미합니다. CartPole 게임은 오른쪽 / 왼쪽 단 두개의 입력만 받는 게임입니다. 따라서 n_action 변수에 정수 2를 담도록 하겠습니다. CartPole manual에 action space는 discrete(2)라고 명시되어 있습니다. 값의 의미도 설명하고 있습니다. action 값이 0일 때 왼쪽으로 카트를 밀라는 뜻이고 1일 때 오른쪽으로 밀라는 뜻입니다.
더 자세한 내용은 gymnasium 패키지 안에 spaces 모듈을 살펴 보아야 합니다. 혹은 원본 코드를 실행해 볼 때 n_action 변수에 어떤 값이 담기는지 살펴봐도 알 수 있습니다.
이번 포스트에서는 spaces 모듈 관련 클래스, 함수 등을 자세히 살펴보지는 않겠습니다.
일단은 간단히 gymnasium 없이 강화학습 코드를 돌리는 것을 목표로 하겠습니다.
Reset
# Get the number of state observations
state, info = env.reset()
reset() 함수를 벗겨내야하는데 이 함수를 당장 내가 전부 짜기에는 너무 어려워보입니다. 이전 포스트에서 살펴본 "justMyCode": false 설정을 통해 열심히 package 내부를 찾아보면 핵심 코드를 열어볼 수 있습니다. cartpole 환경에 관한 소스코드는 아래 경로에서 찾을 수 있습니다.
C:\Users\[사용자이름]\.virtualenvs\AI_proj-PVRbEtys\Lib\site-packages\gymnasium\envs\classic_control\cartpole.py
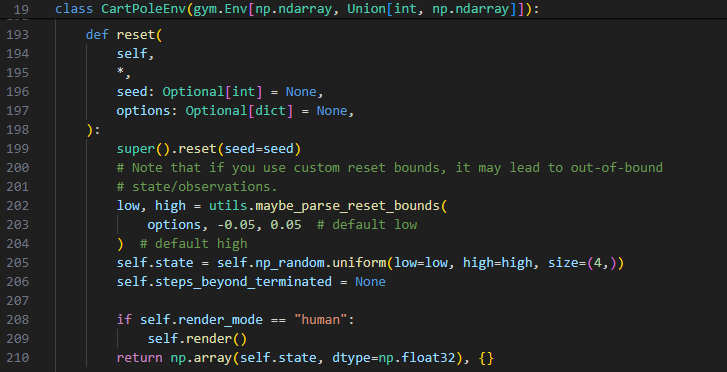
CartPoleEnv 클래스 내부 함수로 reset이 정의 되어있는 것을 볼 수 있습니다. 라인은 193라인부터 210라인까지 입니다. 이 함수 내부 코드가 사실상 몇줄 되지 않습니다. 이렇게 살펴보니 이정도는 우리가 충분히 짤 수 있어 보입니다!
빠르게 살펴 보면 random seed를 설정한 후, 초기 상태의 최대, 최소 값을 설정합니다. 이때 특별한 option이 정의되지 않으면 최소값의 기본값은 -0.05, 최대값의 기본값은 0.05로 설정됩니다. 이후 uniform 분포를 따르는 랜덤값을 생성하는데 크기가 4인 벡터로 생성하고 이 벡터는 상태 벡터입니다. 랜더링 조건이 human이면 랜더링도 수행합니다. 이후 상태 벡터와 빈 dictionary를 반환하는 간단한 함수입니다. steps_beyond_terminated 변수는 무엇일까요? 이 변수는 뒤에서 설명하도록 하겠습니다.
먼저 크기 4의 상태 벡터가 무엇을 의미하는지 공식 메뉴얼에서 찾아보겠습니다. 공식 메뉴얼에 따르면 네개의 값은 순서대로 카트 포지션, 카트 속도, 막대의 각도, 막대의 각속도를 의미합니다. 구현은 spaces 모듈의 box 클래스로 구현되어 있습니다.
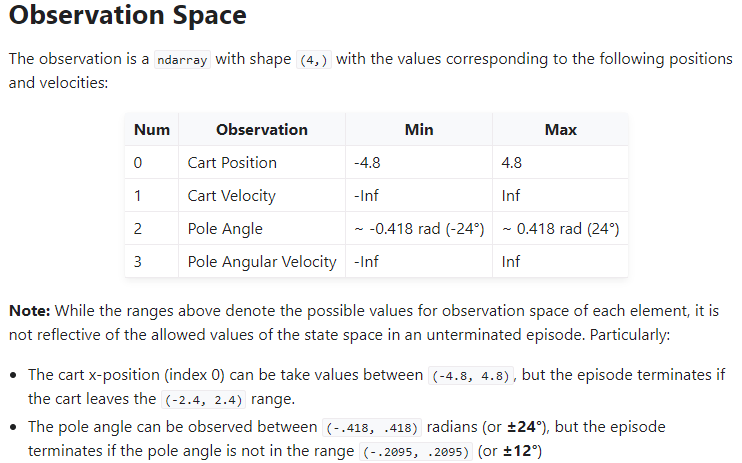
시드 설정 없고 랜더링도 하지 않는다 가정하겠습니다. np_random 이 변수는 numpy에서 정의된 어떤 객체를 담고있을 것으로 유추됩니다. 따라서 그냥 numpy를 직접 import하고 바로 사용하여 uniform() 함수를 불러도 상관없어 보입니다. 불필요한 부분을 제거하여 아래처럼 간단히 함수를 작성해 보았습니다.
import numpy as np
...
def my_reset():
state = np.random.uniform(low=-0.05, high=0.05, size=(4,))
return np.array(state, dtype=np.float32), {}
state, info = my_reset()
Sample
action space는 {0, 1}의 집합이라는 것을 위에서 설명했습니다. sample 함수는 집합의 원소를 무작위로 sampling하는 함수라고 생각할 수 있습니다. (정말 랜덤 선택인지 내부 코드를 보셔도 좋습니다.)
이번에는 numpy가 아닌 기본 random 라이브러리를 사용해 볼까요? 정수 랜덤을 생성하는 함수 여러가지 있는데 randrange를 사용해 보겠습니다. 이 방법을 통해 select_action 함수 내 env 클래스를 다음과 같이 대체해 보았습니다.
def select_action(state):
global steps_done
sample = random.random()
eps_threshold = EPS_END + (EPS_START - EPS_END) * \
math.exp(-1. * steps_done / EPS_DECAY)
steps_done += 1
if sample > eps_threshold:
with torch.no_grad():
# t.max(1) will return the largest column value of each row.
# second column on max result is index of where max element was
# found, so we pick action with the larger expected reward.
return policy_net(state).max(1)[1].view(1, 1)
else:
return torch.tensor([[random.randrange(2)]], device=device, dtype=torch.long)