나만의 gymnasium 패키지 만들기(2)
Intro
이전 포스트까지 우리는 custom 환경을 만드는 법을 알아봤습니다. 이제는 만들어진 환경을 이용해서 실제 강화학습 게임을 진행해 보겠습니다. 사실 거의 대부분의 코드를 cartpole에서 가져올 예정입니다. 즉, cartpole 예제에서 환경만 gridworld로 바꾸는 것이겠죠. 하지만 이렇게 하기 위해 조금씩 손봐야 할 부분이 있습니다.
Wrappers
전 포스트에서 observation 공간을 어떤 클래스로 구현했는지 기억하시나요? 공식 예제에서는 Dict 클래스를 이용하여 구현하였고 이 클래스는 Dictionary 자료형입니다. 이전 포스트에서 observation 공간을 정의하는 부분을 다시 보겠습니다.
self.observation_space = gym.spaces.Dict(
{
"agent": gym.spaces.Box(0, size - 1, shape=(2,), dtype=int),
"target": gym.spaces.Box(0, size - 1, shape=(2,), dtype=int),
}
)
observation_space 라는 변수에는 dictionary 인스턴스를 넣었습니다. 이 dictionary 인스턴스는 내부에 “agent”, “target”이라는 키를 두개 가지고 각 키에 대응하는 값은 Box 클래스로 구현하였습니다. 이 박스 클래스 역시 spaces 모듈의 하위 클래스인 것을 볼 수 있습니다.
Wrappers 모듈은 무엇일까요? 공식 메뉴얼에 따르면 이 모듈은 Gymnasium의 공식 환경 혹은 다른 비공식 환경을 수정할 수 있는 모듈입니다. 이 Wrappers 모듈을 이용하면 다른 특별한 수정 없이 간단히 필요한 부분을 수정할 수 있다고 합니다. 특히나 make() 함수를 이용해 이미 만들어진 환경도 바로 수정할 수 있습니다. 공식 메뉴얼에서 Gridworld의 observation 공간을 처음부터 Box 로 구현하지 않고 Dict 으로 구현한 것은 아마 몰라서가 아니라 이 Wrappers 모듈을 설명하기위해서가 아니었을까 추측해 봅니다. 공식 메뉴얼을 따라서 Wrappers 모듈을 사용해 볼까요?
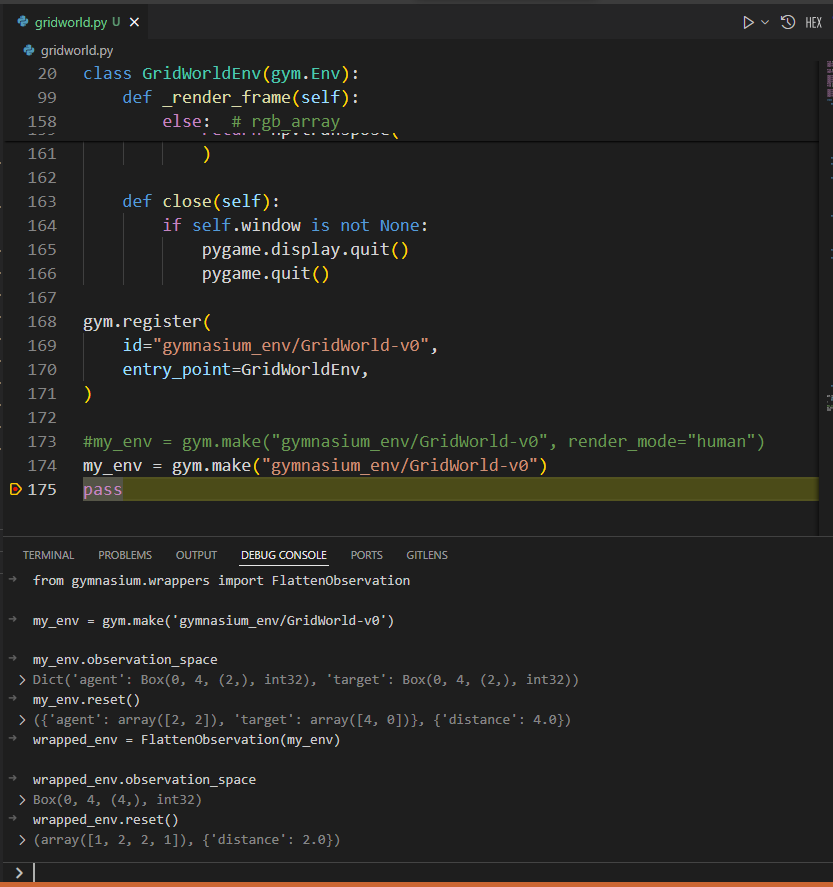
물론 공식 메뉴얼 처럼 python interpreter를 사용해도 되지만 우리는 vscode의 debug console을 사용해 보겠습니다.
전체 코드의 가장 마지막에 pass 코드 한줄 추가하고 여기에 중단점 설정한 후 F5 키를 눌어 실행하겠습니다.
중단점에 걸린 이후 debug console에 메뉴얼을 따라 한 줄 한 줄 넣어보겠습니다.
우리의 환경을 학습 코드에 사용할때 observation 공간은 Dict 자료형 보단 Box 형태로 사용되어한다고 합니다. 이 Dict 자료형의 각각의 벡터를 이어주는 함수가 FlattenObservation 함수이고 바로 적용하여 사용가능합니다. 그림에서 보시면 길이가 2인 Box 2개가 길이가 4인 Box 하나로 펼쳐진 모습을 볼 수 있습니다. Wrapper 모듈을 열심히 찾아보면 FlattenObservation 외에 필요한 다른 함수들도 찾을 수가 있겠군요.
학습 코드
이제 정말 학습 코드를 작성할 준비가 다 되었습니다. 복잡하게 고민하지 말고 cartpole 예제의 코드를 그냥 바로 긁어서 사용하겠습니다. 전체 코드는 아래와 같습니다.
from typing import Optional
import numpy as np
import gymnasium as gym
from enum import Enum
import pygame
import math
import random
import matplotlib
import matplotlib.pyplot as plt
from collections import namedtuple, deque
from itertools import count
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
class GridWorldEnv(gym.Env):
metadata = {"render_modes": ["human", "rgb_array"], "render_fps": 4}
def __init__(self, render_mode=None, size: int = 5):
# The size of the square grid
self.size = size
self.window_size = 512 # The size of the PyGame window
# Define the agent and target location; randomly chosen in `reset` and updated in `step`
self._agent_location = np.array([-1, -1], dtype=np.int32)
self._target_location = np.array([-1, -1], dtype=np.int32)
# Observations are dictionaries with the agent's and the target's location.
# Each location is encoded as an element of {0, ..., `size`-1}^2
self.observation_space = gym.spaces.Dict(
{
"agent": gym.spaces.Box(0, size - 1, shape=(2,), dtype=int),
"target": gym.spaces.Box(0, size - 1, shape=(2,), dtype=int),
}
)
# We have 4 actions, corresponding to "right", "up", "left", "down"
self.action_space = gym.spaces.Discrete(4)
# Dictionary maps the abstract actions to the directions on the grid
self._action_to_direction = {
0: np.array([1, 0]), # right
1: np.array([0, 1]), # up
2: np.array([-1, 0]), # left
3: np.array([0, -1]), # down
}
assert render_mode is None or render_mode in self.metadata["render_modes"]
self.render_mode = render_mode
self.window = None
self.clock = None
def _get_obs(self):
return {"agent": self._agent_location, "target": self._target_location}
def _get_info(self):
return {
"distance": np.linalg.norm(
self._agent_location - self._target_location, ord=1
)
}
def reset(self, seed: Optional[int] = None, options: Optional[dict] = None):
# We need the following line to seed self.np_random
super().reset(seed=seed)
# Choose the agent's location uniformly at random
self._agent_location = self.np_random.integers(0, self.size, size=2, dtype=int)
# We will sample the target's location randomly until it does not coincide with the agent's location
self._target_location = self._agent_location
while np.array_equal(self._target_location, self._agent_location):
self._target_location = self.np_random.integers(
0, self.size, size=2, dtype=int
)
observation = self._get_obs()
info = self._get_info()
if self.render_mode == "human":
self._render_frame()
return observation, info
def step(self, action):
# Map the action (element of {0,1,2,3}) to the direction we walk in
direction = self._action_to_direction[action]
# We use `np.clip` to make sure we don't leave the grid bounds
self._agent_location = np.clip(
self._agent_location + direction, 0, self.size - 1
)
# An environment is completed if and only if the agent has reached the target
terminated = np.array_equal(self._agent_location, self._target_location)
truncated = False
reward = 1 if terminated else 0 # the agent is only reached at the end of the episode
observation = self._get_obs()
info = self._get_info()
if self.render_mode == "human":
self._render_frame()
return observation, reward, terminated, truncated, info
def render(self):
if self.render_mode == "rgb_array":
return self._render_frame()
def _render_frame(self):
if self.window is None and self.render_mode == "human":
pygame.init()
pygame.display.init()
self.window = pygame.display.set_mode(
(self.window_size, self.window_size)
)
if self.clock is None and self.render_mode == "human":
self.clock = pygame.time.Clock()
canvas = pygame.Surface((self.window_size, self.window_size))
canvas.fill((255, 255, 255))
pix_square_size = (
self.window_size / self.size
) # The size of a single grid square in pixels
# First we draw the target
pygame.draw.rect(
canvas,
(255, 0, 0),
pygame.Rect(
pix_square_size * self._target_location,
(pix_square_size, pix_square_size),
),
)
# Now we draw the agent
pygame.draw.circle(
canvas,
(0, 0, 255),
(self._agent_location + 0.5) * pix_square_size,
pix_square_size / 3,
)
# Finally, add some gridlines
for x in range(self.size + 1):
pygame.draw.line(
canvas,
0,
(0, pix_square_size * x),
(self.window_size, pix_square_size * x),
width=3,
)
pygame.draw.line(
canvas,
0,
(pix_square_size * x, 0),
(pix_square_size * x, self.window_size),
width=3,
)
if self.render_mode == "human":
# The following line copies our drawings from `canvas` to the visible window
self.window.blit(canvas, canvas.get_rect())
pygame.event.pump()
pygame.display.update()
# We need to ensure that human-rendering occurs at the predefined framerate.
# The following line will automatically add a delay to keep the framerate stable.
self.clock.tick(self.metadata["render_fps"])
else: # rgb_array
return np.transpose(
np.array(pygame.surfarray.pixels3d(canvas)), axes=(1, 0, 2)
)
def close(self):
if self.window is not None:
pygame.display.quit()
pygame.quit()
gym.register(
id="gymnasium_env/GridWorld-v0",
entry_point=GridWorldEnv,
)
#my_env = gym.make("gymnasium_env/GridWorld-v0", render_mode="human")
my_env = gym.make("gymnasium_env/GridWorld-v0")
from gymnasium.wrappers import FlattenObservation
env = FlattenObservation(my_env)
# set up matplotlib
is_ipython = 'inline' in matplotlib.get_backend()
if is_ipython:
from IPython import display
plt.ion()
# if GPU is to be used
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Transition = namedtuple('Transition',
('state', 'action', 'next_state', 'reward'))
class ReplayMemory(object):
def __init__(self, capacity):
self.memory = deque([], maxlen=capacity)
def push(self, *args):
"""Save a transition"""
self.memory.append(Transition(*args))
def sample(self, batch_size):
return random.sample(self.memory, batch_size)
def __len__(self):
return len(self.memory)
class DQN(nn.Module):
def __init__(self, n_observations, n_actions):
super(DQN, self).__init__()
self.layer1 = nn.Linear(n_observations, 128)
self.layer2 = nn.Linear(128, 128)
self.layer3 = nn.Linear(128, n_actions)
# Called with either one element to determine next action, or a batch
# during optimization. Returns tensor([[left0exp,right0exp]...]).
def forward(self, x):
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
return self.layer3(x)
# BATCH_SIZE is the number of transitions sampled from the replay buffer
# GAMMA is the discount factor as mentioned in the previous section
# EPS_START is the starting value of epsilon
# EPS_END is the final value of epsilon
# EPS_DECAY controls the rate of exponential decay of epsilon, higher means a slower decay
# TAU is the update rate of the target network
# LR is the learning rate of the ``AdamW`` optimizer
BATCH_SIZE = 128
GAMMA = 0.99
EPS_START = 0.9
EPS_END = 0.05
EPS_DECAY = 1000
TAU = 0.005
LR = 1e-4
# Get number of actions from gym action space
n_actions = env.action_space.n
# Get the number of state observations
state, info = env.reset()
n_observations = len(state)
policy_net = DQN(n_observations, n_actions).to(device)
target_net = DQN(n_observations, n_actions).to(device)
target_net.load_state_dict(policy_net.state_dict())
optimizer = optim.AdamW(policy_net.parameters(), lr=LR, amsgrad=True)
memory = ReplayMemory(10000)
steps_done = 0
def select_action(state):
global steps_done
sample = random.random()
eps_threshold = EPS_END + (EPS_START - EPS_END) * math.exp(-1. * steps_done / EPS_DECAY)
steps_done += 1
if sample > eps_threshold:
with torch.no_grad():
# t.max(1) will return the largest column value of each row.
# second column on max result is index of where max element was
# found, so we pick action with the larger expected reward.
return policy_net(state).max(1)[1].view(1, 1)
else:
return torch.tensor([[env.action_space.sample()]], device=device, dtype=torch.long)
episode_durations = []
def plot_durations(show_result=False):
plt.figure(1)
durations_t = torch.tensor(episode_durations, dtype=torch.float)
if show_result:
plt.title('Result')
else:
plt.clf()
plt.title('Training...')
plt.xlabel('Episode')
plt.ylabel('Duration')
plt.plot(durations_t.numpy())
# Take 100 episode averages and plot them too
if len(durations_t) >= 100:
means = durations_t.unfold(0, 100, 1).mean(1).view(-1)
means = torch.cat((torch.zeros(99), means))
plt.plot(means.numpy())
plt.pause(0.001) # pause a bit so that plots are updated
if is_ipython:
if not show_result:
display.display(plt.gcf())
display.clear_output(wait=True)
else:
display.display(plt.gcf())
def optimize_model():
if len(memory) < BATCH_SIZE:
return
transitions = memory.sample(BATCH_SIZE)
# Transpose the batch (see https://stackoverflow.com/a/19343/3343043 for
# detailed explanation). This converts batch-array of Transitions
# to Transition of batch-arrays.
batch = Transition(*zip(*transitions))
# Compute a mask of non-final states and concatenate the batch elements
# (a final state would've been the one after which simulation ended)
non_final_mask = torch.tensor(tuple(map(lambda s: s is not None, batch.next_state)), device=device, dtype=torch.bool)
non_final_next_states = torch.cat([s for s in batch.next_state if s is not None])
state_batch = torch.cat(batch.state)
action_batch = torch.cat(batch.action)
reward_batch = torch.cat(batch.reward)
# Compute Q(s_t, a) - the model computes Q(s_t), then we select the
# columns of actions taken. These are the actions which would've been taken
# for each batch state according to policy_net
state_action_values = policy_net(state_batch).gather(1, action_batch)
# Compute V(s_{t+1}) for all next states.
# Expected values of actions for non_final_next_states are computed based
# on the "older" target_net; selecting their best reward with max(1)[0].
# This is merged based on the mask, such that we'll have either the expected
# state value or 0 in case the state was final.
next_state_values = torch.zeros(BATCH_SIZE, device=device)
with torch.no_grad():
next_state_values[non_final_mask] = target_net(non_final_next_states).max(1)[0]
# Compute the expected Q values
expected_state_action_values = (next_state_values * GAMMA) + reward_batch
# Compute Huber loss
criterion = nn.SmoothL1Loss()
loss = criterion(state_action_values, expected_state_action_values.unsqueeze(1))
# Optimize the model
optimizer.zero_grad()
loss.backward()
# In-place gradient clipping
torch.nn.utils.clip_grad_value_(policy_net.parameters(), 100)
optimizer.step()
if torch.cuda.is_available():
num_episodes = 600
else:
num_episodes = 50
for i_episode in range(num_episodes):
# Initialize the environment and get it's state
state, info = env.reset()
state = torch.tensor(state, dtype=torch.float32, device=device).unsqueeze(0)
for t in count():
action = select_action(state)
observation, reward, terminated, truncated, _ = env.step(action.item())
reward = torch.tensor([reward], device=device)
done = terminated or truncated
if terminated:
next_state = None
else:
next_state = torch.tensor(observation, dtype=torch.float32, device=device).unsqueeze(0)
# Store the transition in memory
memory.push(state, action, next_state, reward)
# Move to the next state
state = next_state
# Perform one step of the optimization (on the policy network)
optimize_model()
# Soft update of the target network's weights
# θ′ ← τ θ + (1 −τ )θ′
target_net_state_dict = target_net.state_dict()
policy_net_state_dict = policy_net.state_dict()
for key in policy_net_state_dict:
target_net_state_dict[key] = policy_net_state_dict[key]*TAU + target_net_state_dict[key]*(1-TAU)
target_net.load_state_dict(target_net_state_dict)
if done:
episode_durations.append(t + 1)
plot_durations()
break
print('Complete')
plot_durations(show_result=True)
plt.ioff()
plt.show()
환경 등록하고 환경을 만들고 observation을 flatten 하게 만든 이후 코드는 cartpole 코드와 완전히 일치합니다! 이제 이 코드를 실행해 볼까요? rendering option을 human으로 설정해서도 돌려봅시다. human으로 설정했을 때 agent가 열심히 target을 찾아 돌아다니는 모습을 볼 수 있습니다.
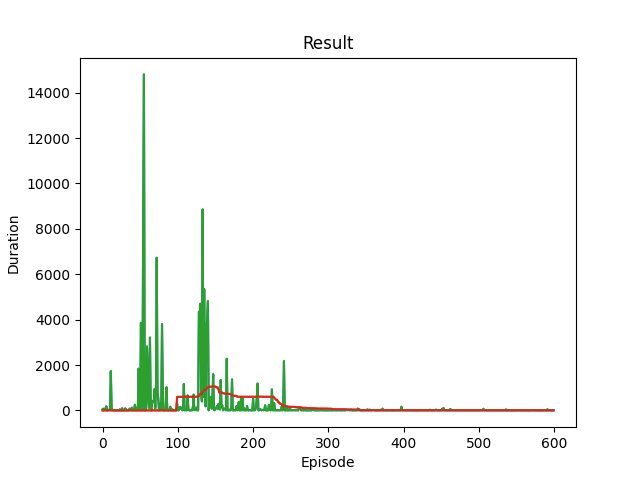
결과 그래프도 보겠습니다. cartpole 예제와는 다르게 이 게임은 duration이 짧아야 게임을 잘 하는 것이겠죠. 학습 초반부에는 target을 잘 찾지 못하는 모습을 볼 수 있습니다. 어떤 episode에서는 무려 14000번이 넘는 이동에도 목적지를 찾지 못하네요. 겨우 5x5, 25칸 grid위에서 이렇게나 많이 돌아다녔습니다. 하지만 학습이 이루어짐에 따라 이동 횟수가 줄어드는 경향을 볼 수 있어 학습이 잘 이루어 지고 있는 것을 알 수 있습니다.